Optimizing Benchpress
Optimizing Benchpress
Recently, I saw the release of nom v6 and decided I wanted to try it out, and see if I could speed up my hobby JS template compiler, BenchpressJS.
Background
Benchpress is a template compiler and tiny runtime which is focused on two things:
- Backwards compatibility with templates.js syntax
- Runtime speed
- (As of 2018) Compilation speed
A short history:
- 2014: templates.js is created as a light library for use in NodeBB.
It used Regular Expressions to fill in template data at runtime, allowing for an unconventional syntax. No precompilation is necessary or possible. - 2017: Benchpress is created as a backwards-compatible replacement for templates.js
It provides much faster runtime performance by compiling templates into Javascript code. - 2018: A compiler rewrite is undertaken utilizing Rust, as the JS compiler (based on Regexp) is quite slow.
This version of the compiler, named benchpress-rs, uses Neon to interface with Node, and is about 30x faster than the JS version.
The JS compiler continues to ship alongside, since pre-built binaries are not available for all platforms. - Nov 7, 2020: Realizing WASM module support is available on all supported version of Node, the JS compiler is removed, and the Rust compiler is shipped solo as a WASM module. Having a single codebase opens up the door to adding more features, but benchpress-rs is pretty hacky and difficult to work on.
- Nov 15, 2020: Another compiler rewrite is finished, using the nom parser combinator library.
This rewrite is optimized to be 4.4x as fast as the previous version, on top of being far more maintainable and extensible.
I'd say a week is pretty good, all things considered
The Drop
Much of the time implementing the rewrite was getting my new version to pass the quite extensive suite of integration tests (especially getting Spans working), but that's not what I'm here to talk about. I'm here to talk about optimizing it after all of that, because I have a shameful secret:
It was slower.
Yep, after all of that work, the end result was actually slower than the previous version. Let's see the benchmarks.
Benchmark Setup
I set up benchmarks both in Rust and Node. Both are based on two large template files: categories.tpl and topic.tpl, which are from some NodeBB at some point I think.
Essentially, each benchmark compiles these repeatedly. Here's what I saw:
Before
$ cargo +nightly bench
running 2 tests
test bench_compile_categories ... bench: 329,287 ns/iter (+/- 120,222)
test bench_compile_topic ... bench: 4,402,767 ns/iter (+/- 63,216) test result: ok. 0 passed; 0 failed; 0 ignored; 2 measured; 0 filtered out $ grunt bench 2>/dev/null
Running "benchmark" task
compilation x 74.70 ops/sec ±0.32% (167 runs sampled) Done.
After
$ cargo +nightly bench
running 2 tests
test bench_compile_categories ... bench: 2,498,374 ns/iter (+/- 11,032)
test bench_compile_topic ... bench: 15,065,914 ns/iter (+/- 51,794) test result: ok. 0 passed; 0 failed; 0 ignored; 2 measured; 0 filtered out $ grunt bench 2>/dev/null
Running "benchmark" task
compilation x 33.88 ops/sec ±0.26% (175 runs sampled) Done.
Woops! That's more than twice as slow. And even worse, the vast majority of that time is spent in Rust.
Flamegraphing
One of the best tools, in my opinion, for finding optimization opportunities is the flamegraph. This neat little figure will show you where the time is spent in your program. So, let's make one with the very handy cargo flamegraph tool:
$ cargo +nightly flamegraph --bin bench # bench refers to a binary based on the benchmarks run before

Isn't it beautiful? Alright let's dig in. Here's how to read the graph, from the flamegraph README:
The y-axis shows the stack depth number. When looking at a flamegraph, the main function of your program will be closer to the bottom, and the called functions will be stacked on top, with the functions that they call stacked on top of them, etc...
The x-axis spans all of the samples. It does not show the passing of time from left to right. The left to right ordering has no meaning.
The width of each box shows the total time that that function is on the CPU or is part of the call stack. If a function's box is wider than others, that means that it consumes more CPU per execution than other functions, or that it is called more than other functions.
The color of each box isn't significant, and is chosen at random.
First, let's ignore anything not above compiler::compile, since that's really what we care about. It's clear that the majority of the program is spent in compiler::parse::tokens, so let's zoom in on that part by clicking on it.
Now we see something like this:
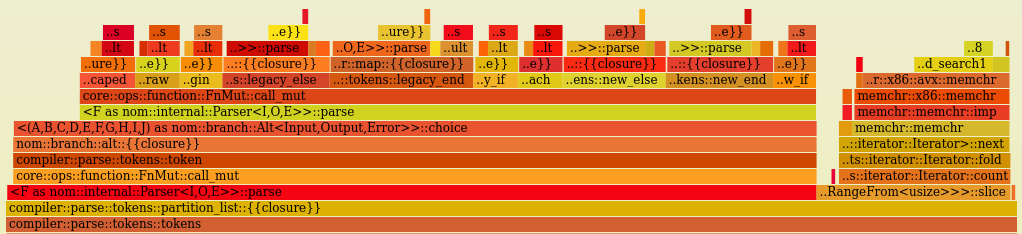
Hmmm. Nothing sticks out to me right off the bat. All of the token parsers seem to be taking a portion of the time that matches what I'd expect.
This had me stumped for a while. Then I figured out what I was missing.
Optimization #1: Token recognition
There are a couple of clues in the flamegraph that give it away:
interp_escapedandinterp_rawshare a similar amount of time. But we should be hittinginterp_escapedway more thaninterp_raw, because escaped interpolation tokens show up far more often in the benchmark templates.- There are a lot of hits on
new_elseandnew_end, but those don't show up in the templates at all. - We're hitting
from_errorandinto_resulta lot, which implies the parsers are erroring a lot.
It turns out, the way token recognition works is extremely expensive. Here's the code:
let mut res = Vec::new();
let mut index = 0; while index < input.len() { match sep.parse(input.slice(index..)) { Err(nom::Err::Error(_)) => { // do-while while { index += 1; !input.is_char_boundary(index) } {} } Err(e) => return Err(e), Ok((rest, mat)) => { // if this match was escaped, skip it if input.slice(..index).ends_with('\\') { let before_escape = input.slice(..(index - 1)); if before_escape.len() > 0 { res.push(f(before_escape)); } input = input.slice(index..); index = nom::Offset::offset(&input, &rest); continue; } if rest == input { return Err(nom::Err::Error(E::from_error_kind( rest, nom::error::ErrorKind::SeparatedList, ))); } if index > 0 { res.push(f(input.slice(..index))); } res.push(mat); input = rest; index = 0; } }
} if index > 0 { res.push(f(input.slice(..index)));
} Ok((input.slice(input.len()..), res))
Do you see it? For every byte in the input, we're running the full parsing suite, checking it against 10 parsers! This works, but it's quite naive. For context, Benchpress tokens come in three shapes:
- Interpolation:
{thing_escaped},{{raw_stuff}} - Modern Control Flow:
{{{ if cond }}},{{{ each arr }}},{{{ else }}},{{{ end }}} - Legacy Control Flow:
<!-- IF cond -->,<!-- BEGIN arr -->,<!-- ELSE -->,<!-- END(IF) stuff -->
Which means that we don't need to check these at every point in the input. We only need to run the parsers when we hit an opening curly brace { or an opening comment-arrow <!--. It just so happens that there's a nice rust library made exactly for the purpose of searching for multiple patterns in text: aho-corasick, which also backs the Rust regex crate.
Let's refactor the code to use that. I also want the refactor to handle escaping tokens here as well. aho-corasick makes this easy: we just need to define the patterns we want to look for, and tell it to use the LeftmostFirst mode, so it will match the escaped patterns we define first before it hits the unescaped start patterns:
static PATTERNS: &[&str] = &["\\{{{", "\\{{", "\\{", "\\<!--", "{", "<!--"]; use aho_corasick::{ AhoCorasick, AhoCorasickBuilder, MatchKind,
};
lazy_static::lazy_static! { static ref TOKEN_START: AhoCorasick = AhoCorasickBuilder::new() .auto_configure(PATTERNS) .match_kind(MatchKind::LeftmostFirst) .build(PATTERNS);
}
Now we can use TOKEN_START in our hot loop to skip over portions of text with no tokens:
pub fn tokens(mut input: Span) -> IResult<Span, Vec<Token<'_>>> { let mut tokens = vec![]; let mut index = 0; while index < input.len() { // skip to the next `{` or `<!--` if let Some(i) = TOKEN_START.find(input.slice(index..).fragment()) { // If this is an escaped opener, skip it if i.pattern() <= 3 { let start = index + i.start(); let length = i.end() - i.start(); // Add text before the escaper character let before_escape = input.slice(..start); if before_escape.len() > 0 { tokens.push(Token::Text(before_escape)); } // Advance to after the escaper character input = input.slice((start + 1)..); // Step to after the escaped sequence index = length - 1; } else { index += i.start(); } } else { // no tokens found, break out index = input.len(); break; } match token(input.slice(index..)) { // Not a match, step to the next character Err(nom::Err::Error(_)) => { // do-while while { index += 1; !input.is_char_boundary(index) } {} } Ok((rest, tok)) => { // Token returned what it was sent, this shouldn't happen if rest == input { return Err(nom::Err::Error(nom::error::Error::from_error_kind( rest, nom::error::ErrorKind::SeparatedList, ))); } // Add test before the token if index > 0 { tokens.push(Token::Text(input.slice(..index))); } // Add token tokens.push(tok); // Advance to after the token input = rest; index = 0; } // Pass through other errors Err(e) => return Err(e), } } if index > 0 { tokens.push(Token::Text(input.slice(..index))); } Ok((input.slice(input.len()..), tokens))
}
This looks cleaner and requires no backtracking for escaped tokens. What did it gain us in performance?
Benchmarks Round 2
$ cargo +nightly bench
running 2 tests
test bench_compile_categories ... bench: 241,765 ns/iter (+/- 4,493)
test bench_compile_topic ... bench: 3,969,554 ns/iter (+/- 43,614) test result: ok. 0 passed; 0 failed; 0 ignored; 2 measured; 0 filtered out $ grunt bench 2>/dev/null
Running "benchmark" task
compilation x 103 ops/sec ±0.38% (176 runs sampled) Done.
Nice! That's even slightly faster than benchpress-rs, so we've made a lot of progress. But there's still room for improvement.
Let's see another flamegraph:
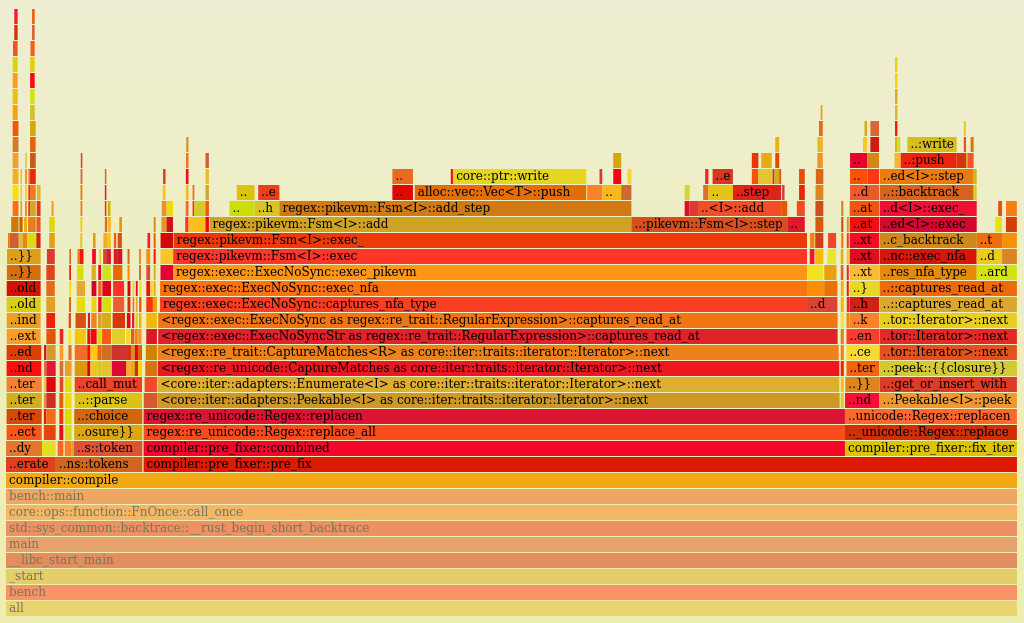
Look at that, tokens parsing is now a small portion of the compilation. This puts a big target on the next step: replacing the prefixer with additions to the parser.
Optimization #2: Prefixer for external keywords
The "prefixer" is what I call a simple backwards-compatibility layer which runs before the parsing step. The prefixer is based on Regular Expressions, which results in it being quite slow. It does a few things:
- Detects keywords like
@value,@key,@indexoutside interpolation tokens, and wraps them in curly braces:{@value} - Detects legacy loop helpers with no arguments like
{function.print_element}, and changes them to be called with the current element as the first argument:{function.print_element, @value} - Detects legacy IF-helpers like
<!-- IF function.works, stuff -->and adds the top-level context as the first argument:<!-- IF function.works, @root, stuff -->, but only if IF conditions - Detects nested legacy
<!-- BEGIN arr -->blocks and duplicates them as<!-- IF ./arr --><!-- BEGIN ./arr -->...<!-- ELSE --><!-- BEGIN arr -->...
The legacy syntax is ambiguous: templates.js would work ifarrwas a top-level value or ifarrwas a property of the current element. Because of this, we have to emit code for both cases.
Let's move the first case into our parser instead of relying on Regex. Luckily, we just made our jobs a lot easier with that refactor of the token recognition. All we need to do is add those keywords to our aho-corasick patterns:
static PATTERNS: &[&str] = &["\\{{{", "\\{{", "\\{", "\\<!--", "{", "<!--", "@key", "@value", "@index"];
And then handle those cases in the tokens parser, parsing them as an expression and adding that to our collection of tokens:
// If this is an escaped opener, skip it
if matches!(i.pattern(), 0..=3) { let start = index + i.start(); let length = i.end() - i.start(); // Add text before the escaper character if start > 0 { tokens.push(Token::Text(input.slice(..start))); } // Advance to after the escaper character input = input.slice((start + 1)..); // Step to after the escaped sequence index = length - 1;
// If this is an opener, step to it
} else if matches!(i.pattern(), 4..=5) { index += i.start();
// If this is `@key`, `@value`, `@index`
} else { let start = index + i.start(); let end = index + i.end(); let span = input.slice(start..end); let (_, expr) = expression(span)?; // Add text before the token if start > 0 { tokens.push(Token::Text(input.slice(..start))); } // Add token tokens.push(Token::InterpEscaped { span, expr }); // Advance to after the token input = input.slice(end..); index = 0;
}
Let's remove the relevant parts of the prefixer and see what this bought us.
Benchmarks Round 3
$ cargo +nightly bench
running 2 tests
test bench_compile_categories ... bench: 194,683 ns/iter (+/- 5,158)
test bench_compile_topic ... bench: 2,109,842 ns/iter (+/- 26,943) test result: ok. 0 passed; 0 failed; 0 ignored; 2 measured; 0 filtered out $ grunt bench 2>/dev/null
Running "benchmark" task
compilation x 172 ops/sec ±0.26% (176 runs sampled) Done.
Another nice boost to our compilation speed. Onward!
Optimization #3: Legacy loop helpers
Our second prefixer case is quite simple: when we encounter a legacy helper called with no arguments, we need to implicitly call it with @value. This we can implement in the expression parser.
Before, we just provided an empty argument list to a legacy helper:
fn legacy_helper(input: Span) -> IResult<Span, Expression<'_>> { map( consumed(pair( preceded(tag("function."), identifier), opt(preceded( ws(tag(",")), separated_list0(ws(tag(",")), expression), )), )), |(span, (name, args))| Expression::LegacyHelper { span, name, args: args.unwrap_or_default(), // Provides an empty Vec }, )(input)
}
But now, we want to give it @value in those cases, which we can achieve with Option::unwrap_or_else:
args: args.unwrap_or_else(|| { // Handle legacy helpers without args being implicitly passed `@value` vec![Expression::Path(vec![PathPart::Part(Span::new_extra( "@value", input.extra, ))])] }),
Let's see the benchmarks with this removed from the prefixer.
Benchmarks Round 4
$ cargo +nightly bench
running 2 tests
test bench_compile_categories ... bench: 187,462 ns/iter (+/- 2,519)
test bench_compile_topic ... bench: 2,030,519 ns/iter (+/- 19,016) test result: ok. 0 passed; 0 failed; 0 ignored; 2 measured; 0 filtered out $ grunt bench 2>/dev/null
Running "benchmark" task
compilation x 180 ops/sec ±0.32% (181 runs sampled) Done.
Not a huge bump, likely because this doesn't show up a ton in templates, but an improvement nonetheless.
Optimization #4: Legacy IF helpers
Next step in my quest to dismantle the prefixer is to handle <!-- IF function.foo, bar -->. Essentially, I need to check if the conditional is a legacy helper expression, and if so, prepend the arguments with @root. We can implement this in the token parser.
Before, we just provided the unmodified expression:
fn legacy_if(input: Span) -> IResult<Span, Token<'_>> { map( consumed(delimited( pair(tag("<!--"), ws(tag("IF"))), ws(consumed(expression)), tag("-->"), )), |(span, (subject_raw, subject))| Token::LegacyIf { span, subject_raw, subject, // Unmodified expression }, )(input)
}
Rust's extensive pattern-matching makes it easy to check for a LegacyHelper expression, and modify it accordingly:
subject: { // Handle legacy IF helpers being passed @root as implicit first argument if let Expression::LegacyHelper { span, name, mut args } = subject { args.insert(0, Expression::Path(vec![PathPart::Part(Span::new_extra( "@root", input.extra, ))])); Expression::LegacyHelper { span, name, args } } else { subject } },
This fix step was implemented with a pretty nasty Regex, so I expected a pretty substantial performance improvement.
Benchmarks Round 5
$ cargo +nightly bench
running 2 tests
test bench_compile_categories ... bench: 196,249 ns/iter (+/- 13,057)
test bench_compile_topic ... bench: 2,028,033 ns/iter (+/- 16,110) test result: ok. 0 passed; 0 failed; 0 ignored; 2 measured; 0 filtered out $ grunt bench 2>/dev/null
Running "benchmark" task
compilation x 178 ops/sec ±0.37% (178 runs sampled) Done.
But really, performance was about the same, because this pattern actually never shows up in the benchmark templates. That's okay though, let's move on.
Optimization #5: Ambiguous inner BEGIN
With those taken care of, the only thing left is handling this:
<!-- BEGIN people --> person {people.name} has the following pets: <!-- BEGIN pets --> - {pets.name} <!-- END pets -->
<!-- END people -->
The inner pets loop is ambiguous. There's no way for the compiler to know that it should refer to the pets for each element of people. It could also refer to the top-level pets value. So we must emit code for both cases, by transforming it to this:
<!-- BEGIN people --> person {people.name} has the following pets: <!-- IF ./pets --><!-- BEGIN ./pets --> - {pets.name} <!-- END pets --><!-- ELSE --><!-- BEGIN pets --> - {pets.name} <!-- END pets --><!-- ENDIF ./pets -->
<!-- END people -->
This will be the most difficult to move into code. I won't bore you with the details, but here's a quick run-down. When this condition is detected, we interpret the tokens ahead both as if it was a relative path and as if it was an absolute path, then wrap those in a conditional. Otherwise, we emit it as we would normally.
Rust's closures help with this immensely, allowing me to deduplicate the code into a closure, which I call depending on the case.
// create an iteration intruction
Token::LegacyBegin { span, subject, subject_raw,
} => { let normal = |input: &mut I, subject| { let mut body = vec![]; let mut alt = vec![]; let subject = resolve_expression_paths(base, subject); let base: PathBuf = if let Expression::Path(base) = &subject { let mut base = base.clone(); if let Some(last) = base.last_mut() { last.with_depth(depth) } base } else { base.to_vec() }; match tree(depth + 1, &base, input, &mut body)? { Some(Token::LegacyElse { .. }) | Some(Token::Else { .. }) => { // consume the end after the else match tree(depth, &base, input, &mut alt)? { Some(Token::LegacyEnd { .. }) | Some(Token::End { .. }) => {} _ => return Err(TreeError), } } Some(Token::LegacyEnd { .. }) | Some(Token::End { .. }) => {} _ => return Err(TreeError), } Ok(Instruction::Iter { depth, subject_raw, subject, body, alt, }) }; // Handle legacy `<!-- BEGIN stuff -->` working for top-level `stuff` and implicitly `./stuff` match &subject { Expression::Path(path) if depth > 0 && path.first().map_or(false, |s| { // Not a relative path or keyword !s.inner().starts_with(&['.', '@'] as &[char]) }) => { // Path is absolute, so create a branch for both `./subject` and `subject` let mut relative_path = vec![PathPart::Part(Span::new_extra("./", span.extra))]; relative_path.extend_from_slice(path); let relative_subject = Expression::Path(relative_path); Instruction::If { subject: resolve_expression_paths(base, relative_subject.clone()), body: vec![normal(&mut input.clone(), relative_subject)?], alt: vec![normal(input, subject)?], } } _ => normal(input, subject)?, }
}
Yes! The prefixer is gone. Time for a final set of benchmarks.
Final Benchmarks
$ cargo +nightly bench
running 2 tests
test bench_compile_categories ... bench: 111,440 ns/iter (+/- 4,479)
test bench_compile_topic ... bench: 944,981 ns/iter (+/- 6,062) test result: ok. 0 passed; 0 failed; 0 ignored; 2 measured; 0 filtered out $ grunt bench 2>/dev/null
Running "benchmark" task
compilation x 327 ops/sec ±0.53% (180 runs sampled) Done.
Check that out! We're 10x faster than we started, and 4.4x faster than benchpress-rs. Fantastic.
Let's take a final look at the flamegraph:
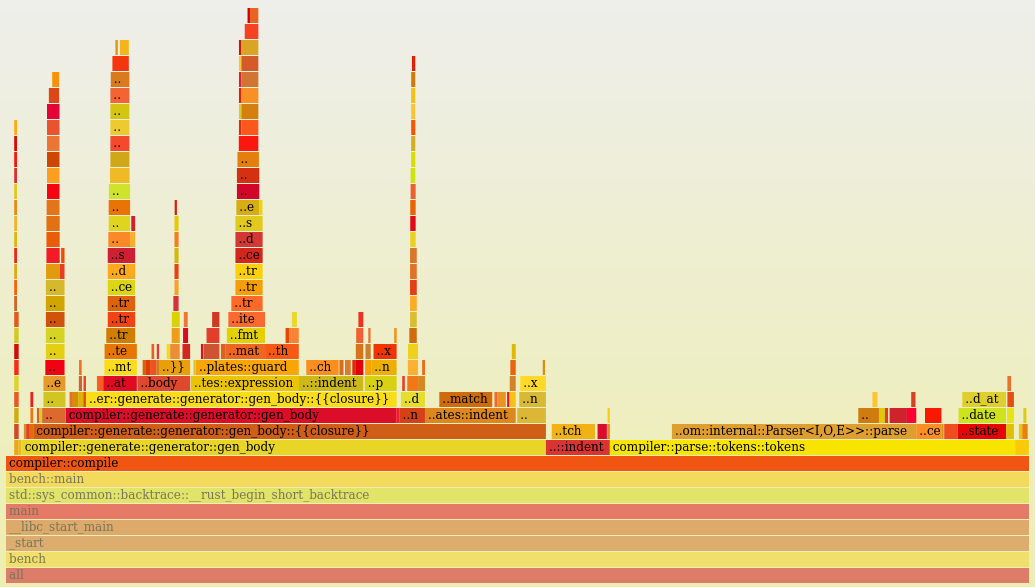
Now we can see that our program spends about equal time parsing and generating output.
Final Remarks
After all of that, I was quite proud of myself. Ditching the prefixer also has a huge side-benefit: true source location information. Having that information allows me to emit some helpful Rust-inspired warnings like this:
[benchpress] warning: keyword outside an interpolation token is deprecated --> tests/templates/source/loop-tokens-conditional.tpl:3:39 | 3 | <span class="label label-primary">@key</span> | ^^^^ help: wrap this in curly braces: `{@key}` | note: This will become an error in the v3.0.0
Overall, I'm very happy with nom. It made the rewrite much easier than it would have been, had I tried to custom write another parser. It made the resulting code much easier to read and more maintainable. And without its flexibility, I would never have been able to refactor out the prefixer.